Figure 1
This web page publishes SAX Parser code that reads XML formatted data into Java objects. A class is included that will allocate and initialize the SAX Parser. If a boolean flag is true, the parser will be initialized as a validating parser. The XML schema that the XML documents are validated against is published here as well.
A related web page provides an example of how the DOMParser can be used to process arithmetic expressions, in XML format.
The SAXParser and related objects can be downloaded from:
The example software discussed on this web page can be downloaded via links listed below.
With SAX and XML Schema validation as examples, I am left with the impression that the people who developed these technologies never took a compiler implementation class, or if they did, the class left no impression on them.
Parsing is usually done by two logical components: a parser and a scanner. The scanner reads the text and classifies it as "tokens". A token is a catagory that is recognized by the parser. For example, a scanner for the Java programming language might return the tokens that include: identifier, integer, for (a reserved word), mult (an operator). An important point, relative to SAX, is that the parser calls the scanner. As the parser processes the tokens returned by the scanner it performs operations, like building a syntax tree. An example of a parser that reads assignment statements and arithmetic expressions and builds XML can be found here. The is part of the DOM parsing software mentioned above.
In the case of SAX, the scanner (the SAXParser object) calls the parser. This makes parsing with SAX needlessly awkward and complicates the architecture of the software. For this reason, the DOMParser is frequently used for parsing complicated XML documents.
The SAXParser does have two notable advantages over the DOMParser: the SAXParser is faster and it uses less memory. While the SAXParser is difficult to use for processing complex XML documents, perhaps it is appropriate for processing simple XML documents? This web page grew out of an experiment to see if this is true.
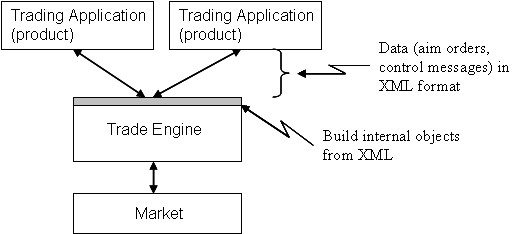
The prototype code published on this web page is motivated by a real application. This is a software system I call a Trade Engine, which is diagrammed in Figure 1. The Trade Engine is designed to process order and control messages for trading applications. These might be computer driven trading programs for the stock, options or foreign exchange markets. The trading applications submit XML formatted orders and control messages to the Trade Engine. The Trade Engine parses and validates these messages and builds internal Java objects. The market orders are called "aim orders" because they specify a trading goal. Depending on the processing instructions, the Trade Engine may execute the order over a period of time (e.g., the trading day).
Figure 1
SAX uses "call backs". When the SAXParser object recognizes a component in an XML document (e.g., a start Element, an end Element, the characters between tags), it calls a method that may be supplied by the application to process the XML component. In Java this is done by subclassing a handler class, like the DefaultHandler. This can be seen in the method signature in the javax.xml.parsers.SAXParser object for the parse method used in this example:
parse(InputStream is, DefaultHandler dh)
In this example a MessageProcessor subclass is derived from the DefaultHandler class. The MessageProcessor class overrides the methods associated with the XML components that are of interest. For example, startElement is overridden, but the processingInstruction() method is not. The MessageProcessor class is diagrammed in Figure 2.
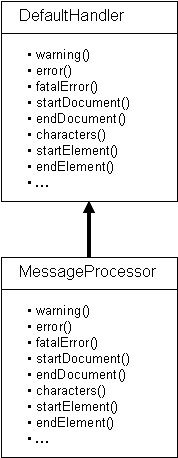
The result of the SAXParser calling the methods overridden by the MessageProcessor class is to build an object from the data. All Trade Engine objects share a common set of fields indicating the product that sent the message, the user and a local ID that is used by the product. The specific messages have unique data that is associated with that message type. This is experimental prototype code, so only two message types, Control and AimOrder are supported. This is shown in the Figure 3.
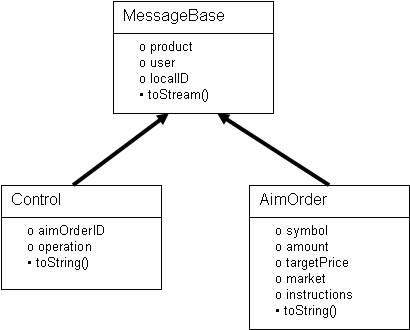
Figure 3
A Trade Engine message may enclose multiple sub-messages. For example, one Trade Engine message may include multiple aim orders. When the MessageProcessor class recognizes the start of a sub-message it allocates a sub-message processor. The MessageProcessor then calls the sub-message processor methods to process each of the XML components and build the object. The class diagram for the sub-message processors is shown in Figure 4. Again, this is just a prototype, so there are only two message processors.
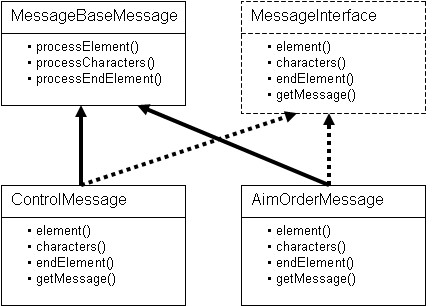
Figure 4
The MessageBaseMessage base class processes the common data fields in the MessageBase object, which is the base class for the Control and AimOrder objects.
The software published here builds message objects from XML formatted data. In theory using the SAXParser for this is faster than using the DOMParser to build a DOM object and then traversing the DOM tree to build a message object. But the call back architecture of SAX introduces complexity that does not exist for a parser which calls a scanner. The awkwardness of SAX and the overhead of DOMParsing are some of the motivations behind the XML Pull Parser, which is called by a parsing application. An example that applies XML Pull Parsing to the Trade Engine messages described on this web page can be found here.
One advantage that both the SAX and DOM parsers have is that they are validating. The structure of the XML document can be verified against an XML schema. However, the computational cost of this validation is unknown (at least to me). SAX validation may reduce the computational advantage of the SAX parser compared to the DOM parser.
The Java source for the SAX parsing application describe here can be downloaded as either a jar or tar file:
To unpack these files use either:
tar xvf saxparse.tar
jar xvf saxparse.jar
The saxparse classes use the TypeSafeEnum classs. The TypeSafeEnum class is discussed on this web page.
The doxygen program can be used to generate HTML formatted documentation from Java (or C++) source code. Unlike Javadoc, doxygen can be used to generate documentation that includes source code, class diagrams and UML diagrams.
Doxygen formatted documentation can be found here
The SAX parser code uses the same set of libraries as the DOMParser expression evaluation code. Please see the note Java: compile once, run anywhere....
The source code is published with the following copyright:
Copyright Ian Kaplan 2004, Bear Products International You may use this code for any purpose, without restriction, including in proprietary code for which you charge a fee. In using this code you acknowledge that you understand its function completely and accept all risk in its use.
You may include this source code in Free Software projects, but you need to keep my copyright with my software. This copyright is less restrictive than the GNU Free Sofware "copyleft", since you may use this software in a "closed source" project.
Building and Processing XML in Java
This web page publishes Java source code that demonstrates how to build XML Document objects. It also publishes code that shows how to parse, validate and process XML. An XML Document object is build from an arithmetic expression or assignment statement (e.g., x = 3 + 4 * 5). The resulting XML Document is then "serialized" to a String object. The String is then read by an XML parser, validated and convered to an XML DOM object. The DOM tree is traversed and the expression (or statement) is evaluated). The XML construction and evaluation objects are used to construct an interactive expression processor.
Processing XML with the XML Pull Parser
As noted above, the way SAX processes XML is "ass backward". The SAX parser calls code in the application what parses the XML document. The XML Pull Parser uses a standard parsing architecture and can be called by the parsing application.
Building an in-memory tree with the Xml Pull Parser
This web page publishes a remarkably small object that builds an in-memory tree representation of an XML document using the XmlPullParser. A tree-to-XML serializer is also included.
Ian Kaplan, August 2004
Revised:
