Figure 1
When it comes to complex XML documents, processing is easier when the document is represented as an in-memory tree. The in-memory tree can then be traversed and/or modified to produce a result.
The Java DOMParser object is frequently used to read an XML document, optionally validate it against an XML schema and build an in-memory tree in the form of a Document object.
XML is being used to represent more and more forms of information. As a result, XML source documents that are multiple megabytes in size may be encountered. For large XML documents the DOMParser and the Document object it builds have some disadvantages. The DOMParser is slow, compared to the SAXParser and the XmlPullParser. The Document object consumes a significant amount of memory. One of my colleagues mentioned that the Document object is three times larger than the original XML source (I have not verified this). Although the Document object has a standard API which abstracts the actual representation of the tree, the Document API is awkward compared to a simple tree data structure.
This web page publishes Java source code that demonstrates how an in-memory tree, which mirrors the XML source document, can be rapidly constructed using the XmlPullParser. This tree is light weight and designed to be easy to traverse and modify. The XmlPullParser is as fast or faster than the SAXParser and much faster than the DOMParser. Without proof, I will also speculate that the tree is also more memory efficient than the Document object built by the DOMParser.
The most significant advantage that the DOMParser has over the in-memory tree builder published here is that the DOMParser can validate against an XML schema. While validation is part of the API for the XmlPullParser, the code that implements this API does not currently support validation. The XmlPullParser will, however, make sure that the XML is properly formed.
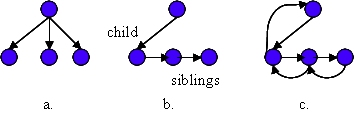
The in-memory tree that is constructed by the TreeBuilder object published here is based on a tree data structure that is popular in constructing the data structures built by compilers. Figure 1 attempts to explain this data structure.
Figure 1
Figure 1a shows a tree node that has tree children. In this picture, there are three links, one to each child. Implementing a data structure that exactly implements such a tree can be awkward. How will the links be represented? If they are represented as an array of references, should the array be fixed size or growable? If the number of links if fixed, then different tree node types might exist: unary (one child), binary (two children), ternary, and N-ary for example.
I once worked on a compiler (designed by someone else) where the compiler intermediate (the abstract syntax trees) had different types for nodes with different numbers of children. The code turned out to be more awkward than it had to be. Sections of code that traversed the tree had to test for the node type (e.g., if (unary) else if (binary) etc...)
If the number of links is not fixed and a growable array is used, then there is the extra memory overhead to manage the growable array and parameters like size.
Figure 1b shows one solution to this problem. Figure 1b implements the tree shown in Figure 1a. Each node has a child reference and a sibling reference. If the top node is root then a reference to the second child of the root node would be root.getChild().getSibling(). Tree walkers and iterators that process the children can be implemented with regular code. An iterator over the children of root is shown below:
for (Node t = root.getChild(); t != null; t = t.getSibling()) {
processChild( t );
}
In some cases the tree walker will modify the tree as it walks over it. In Java, where there are no references to references (e.g., a pointer to a pointer like ptr** in C/C++), a pointer to the parent and previous sibling allows trees to be modified in-place. This is shown in Figure 1c.
As noted elsewhere on these web pages, the XmlPullParser implements XML scanning/parsing correctly. This allows XML parsing applications to be efficiently constructed. Figure 2 shows the core of the recursive code that translates an XML source document into an in-memory tree. Even though I wrote this code, I was surprised at how small it was. There are some support functions to build tag nodes, with their associated attribute lists, but this is pretty much all there is to building an in-memory tree with the XmlPullParser.
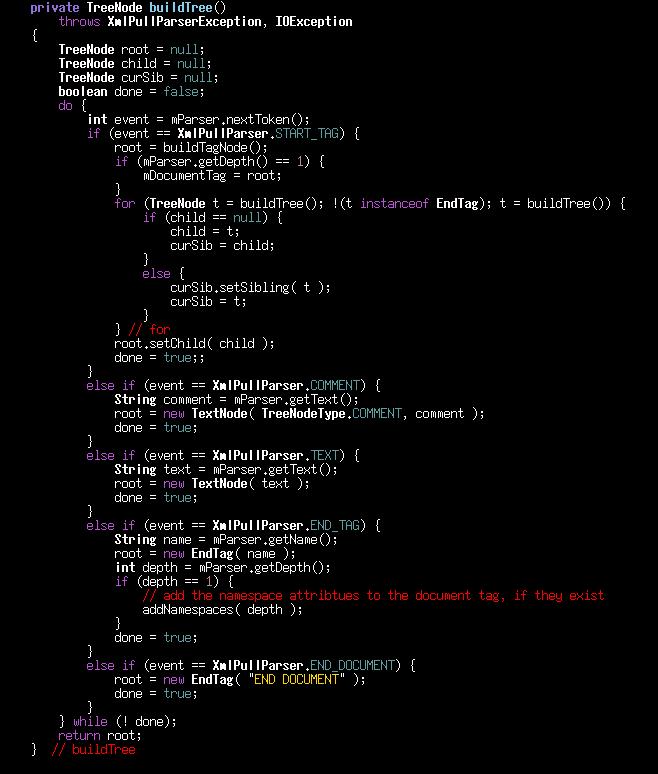
Figure 2
The XmlPullParser and its application in parsing simple XML documents is discussed on the companion web page Processing XML with the XML Pull Parser. This web page also describes where you can get the source for the XmlPullParser and its copyright.
The Java source code for the XML to in-memory tree builder can be downloaded below. This code also includes an in-memory tree to XML serializer. Using this code as a base, an application can be constructed that reads an XML source document into an in-memory tree, modifies the tree and then writes out a new XML document.
To unpack these files use either:
tar xvf treebuilder.tar
jar xvf treebuilder.jar
Doxygen formatted documentation for the TreeBuilder and related classes can be found here.
Building and Processing XML in Java
This web page publishes Java source code that demonstrates how to build XML Document objects. It also publishes code that shows how to parse, validate and process XML. An XML Document object is build from an arithmetic expression or assignment statement (e.g., x = 3 + 4 * 5). The resulting XML Document is then "serialized" to a String object. The String is then read by an XML parser, validated and convered to an XML DOM object. The DOM tree is traversed and the expression (or statement) is evaluated). The XML construction and evaluation objects are used to construct an interactive expression processor.
Processing XML with the XML Pull Parser
This web page provides a basic introduction to the XmlPullParser. To compare the XmlPullParser and the SAXParser, this web page publishes code for a simple parsing application, which is also implemented in SAX (see below).
The DOMParser and the DOM object it builds are useful for processing complex XML documents. However, DOM may impractical for very large XML documents because of its memory use. Also, the construction and traversal of a DOM object has a computational cost.
The SAXParser is an alternative to the DOMParser. This web page publishes example SAXParser code that processes prototype messages that might be used a Trade Engine, a software system that supports computer driven trading.
Ian Kaplan, September 2004
Revised:
